My first post in this series described in some detail a one-bit slice of the ALU, and identified quite a number of control signals that feed all 32 bit slices which determine how the ALU operates. Now that I've reverse-engineered the overall instruction decoding and sequencing mechanism we now have enough context to make a start on reverse-engineering the circuitry that generates the ALU's control signals. This turns out to be more complex than I first expected and a full understanding of what's happening will probably have to wait until other parts of the processor have also been reverse-engineered.
Let's make a start by setting the context. The ALU circuit from my earlier post is reproduced below; we'll need to refer to it as we proceed.

The location of this circuitry, and it's control circuitry, on the silicon are as follows:

Let's now zoom in on the ALU control area:

The ALU Control Logic comprises two distinct areas - (1) a bunch of "ad-hoc" gates and drivers sitting just above the ALU itself, and (2) just above them, a Programmable Logic Array which is referred to as PLA-1 in an earlier blog. In the same area is the logic which implements the Program Status Register which is not discussed here.
The overall circuit is as follows:

The circuit diagram is laid out roughly as it is in the silicon - a bunch of control signals come in from above and feed PLA-1; the buffered PLA-1 outputs, and a couple of outputs from the instruction-decoder, then feed downwards to provide the control signals to all 32 bit slices that form the ALU. Not surprisingly, these control signals tally exactly with the signals in the ALU circuit at the beginning of this blog.
The Carry Logic on the left (highlighted in blue) feeds the Carry bit from the PSR Logic (node 8083) to bit 0 of the ALU. The Carry bit is delayed by a single clock cycle using a dynamic latch (I've used a D latch symbol for ease of drawing) and conditioned by two outputs of the PLA as per the following truth table:

The Dynamic Register Control circuitry on the RHS (highlighted in orange) shows that the two dynamic latches in the ALU (one on each operand path) are controlled by outputs on PLA-2 (the instruction decoder), with latching occurring on the trailing edge of the Phase 1 clock. the Operand 1 latch is also operated one clock cycle after the PLA-2 signals (8062, 8061, 8060) are all simultaneously low. We'll try to make sense of the purpose of this part of the circuit later.
PLA-1 Content - Input Decoding
After all this context setting it's now time to look at what's in PLA-1. The PLA layout is very similar to the instruction decoder PLA-2 described earlier:

The 8 input selection signals enter the PLA from the lower right and the signals, and their inverted versions, feed 16x vertical columns. Which transistors are fitted (or missing) determine which one of the 31 rows within the PLA is selected. There are further details about the operation of this circuit in the earlier blog post.
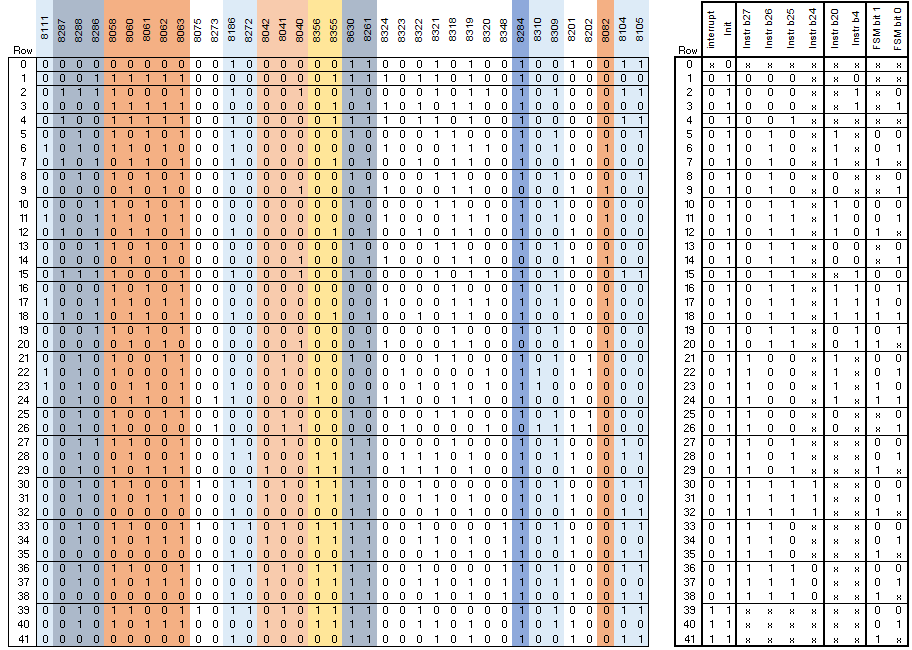
Let's start with the row selection logic on the RHS of the PLA, a raw dump of which is below (with the top row of the table corresponding to the top row in the PLA):

The content displayed in this format doesn't give us much insight into what is happening. However, after a little study the following pattern emerges:

It becomes clearer that the 3x inputs from PLA-2 (8062, 8061, 8060) form a "command" that narrows down which row will be selected. (Note that I've shown these 3x signals in the order that they enter PLA-1; similarly the earlier description shows these signals in the order that they exit PLA-2 - but they are in a different order! This is the way the chip is wired! So you need to remember to swap the bit ordering when you compare the data between the two PLAs!)
Let's start by looking closer at the first command: "111" from PLA-2, which narrows the selection to rows 15-30. If we refer to the PLA-2 logic table & find which rows generate a "111" (remembering to reverse the bits, which happens to not matter in this case), we find it appears on three rows: 1, 3, and 4 (highlighted in light blue).

All three rows are associated with the last (or only) cycle of a DP (Data Processing) instruction. So, returning to the PLA-1 table above, the signals on the Instruction Bus b24 to b21 are from a DP instruction. The DP instruction format is:

And, as expected, we see that b24 to b21 correspond to the "Operation Code" - AND, OR, etc. So we can conclude that rows 15 to 30 of PLA-1 correspond to each ALU operation.
By following a similar process and taking each of the remaining commands in turn we can gain some understanding of what rows 0..14 are for. However this analysis reveals lots of specific details - there is a lot of complexity here. The annotated PLA-1 row-selection table is as follows:

What's clear from this table is that the ALU is being used for a lot more than the DP instructions that are visible to the programmer - almost half of this table is for other purposes! In the main the use of Instruction Register bits 24..21 makes sense given the context. The one exception is for command "000" (rows 0, 1 above); the Instruction Register bits are only valid & meaningful on a couple of the 9 rows this command is used. I suspect that this command is sometimes used as a "no-op".
We can also perhaps gain some insight into what the signal "From Trap Ctrl (8158)" is. It only influences the row decoding for rows 6, 7 which is associated with LDR and LDM instruction execution. We know from the instruction descriptions that there are special rules in cases where a data fetch abort occurs:
- for the LDR instruction: "The data fetch may abort, and in this case, the base and destination modifications are prevented",
- for the LDM instruction: "If an abort occurs...the final cycle is altered to restore the modified base register")
Perhaps this logic is to implement this functionality?
PLA-1 Content - Output Values
Now that we've made an initial analysis of the input decoding, it's time to see what sense we can make of the output values. The table below is laid out to reflect the physical layout and therefore shows the output values on the LHS. There are also some notes on the left.

There is an awful lot of information contained in this table!
Let's start with the DP rows - 15 to 30:
- The good news is that on rearranging the order of the 6 right-most output columns, these values exactly correspond to the table that appeared in my first post on the ALU! Whew!
- If we now look at the output columns for 8087, 8088, we know from the earlier circuit diagram that these values determine what signal is fed to the Carry In on bit 0 of the ALU. And we only need to look at those rows where the output signal "/Enable C chain" (8116) is 0 (since the Carry signal is ignored otherwise). The comments on the left captures the results. The Carry In signal is set to exactly the values we would expect for associated op-code.
- The first output, "To INST SKIP logic (8065)" is interesting in that it is only zero for the 4x comparison op-codes. About these op-codes the documentation states: "They are used only to perform tests and to set the condition codes on the result, and therefore should always have the S bit set" (we can see from the DP instruction format above that the S bit is defined as "Set Condition Code", 0 = Do not alter condition codes, 1 = Set condition codes). I suspect that this output from the PLA is used by the INST SKIP logic to detect if this is an invalid instruction.
- The output "To PSR Logic (8064)" appears to control when the PSR is updated. Since 8064 is high for all the DP op-codes, and low for all other ALU operations, it probably controls when the Carry, Overflow, Negative, and Zero flag can be updated (subject of course to the S bit, as described earlier).
- The output "To PSR Logic (8059)" is only high when an arithmetic operation (as opposed to a logical operation) is taking place. It therefore selects where the Carry flag is updated from - either the ALU output, or the result of the shift operation, and whether the Overflow flag is updated or not. See p2-32 of the VTI arm data book (1990) for a more complete description of the rules regarding how the PSR bits are updated.
Now that we've completed analysing the DP instructions, let's move the remainder of the table - rows 0 to 14.
To analyse rows 0 to 14 of the PLA-1 output table I assumed that the ALU would be carrying out similar operations to the DP instructions we've already been looking at. I therefore expected to see the same output settings on these rows as the rows we've already analysed. The results of this comparison work are shown in the Notes on the left of the table above. A summary is:
- Matches: There are 8 rows with exact matches, and select a variety of ALU op-codes: MOV, ADD, SUB, RSB (reverse substract).
- Variants: A further 5 rows match, apart from the Carry In selection. These are described further below.
- Unknowns: Two rows have identical values, but don't match any DP instruction.
Let's look further at the variants. Although they appear on 5 rows, there are just two versions:
- ADD (but Cin = 1). The normal ADD has a Cin = 0, so this variant has the result = Op1 + Op2 + 1 (where Op1 and Ap2 are the two operands presented to the ALU).
- RSB (but Cin = 0). The normal RSB has a Cin = 1, so this variant has the result = Op2 - Op1 - 1.
We can make educated guesses as to what is happening on each of these rows. For instance, on row 2, we are executing a Branch or Branch and Link instruction, and are almost certainly calculating the destination address by adding the PC to the PC-relative offset which appears within the instruction (we've seen in an earlier article how there is logic in the Read Bus B that extracts the 24 bit offset).
Conclusion
It turns out that the ALU control logic is more complex than I expected. What is clear is that the chip designers really maximised the use of the ALU!
Whilst I've completely reverse-engineered the control circuitry, I've only made a start on unraveling what is actually going on. A full understanding requires some more analysis of the circuitry itself, and on getting a wider view on what is happening elsewhere on the chip. My list of "to-do" items includes:
- What exactly is the "unknown" ALU command we discovered above?
- What values appear at the inputs to the ALU (Operand 1 and operand 2) for each of the rows above (this requires other parts of the processor to be reverse-engineering first). This will also give us a better understanding of why the variants to the ADD, RSB opcodes are introduced.
- What exactly is being latched into the ALU's dynamic registers, and what is the sequencing associated with this? And why does the circuit above have the specific logic to introduce a one cycle delay for when DP instructions are executed?